A Graph-Based Approach for Category-Agnostic Pose Estimation
Abstract
Traditional 2D pose estimation models are limited by their category-specific design, making them suitable only for predefined object categories. This restriction becomes particularly challenging when dealing with novel objects due to the lack of relevant training data. To address this limitation, category-agnostic pose estimation (CAPE) was introduced. CAPE aims to enable keypoint localization for arbitrary object categories using a few-shot single model, requiring minimal support images with annotated keypoints. We present a significant departure from conventional CAPE techniques, which treat keypoints as isolated entities, by treating the input pose data as a graph. We leverage the inherent geometrical relations between keypoints through a graph-based network to break symmetry, preserve structure, and better handle occlusions. We validate our approach on the MP-100 benchmark, a comprehensive dataset comprising over 20,000 images spanning over 100 categories. Our solution boosts performance by 0.98% under a 1-shot setting, achieving a new state-of-the-art for CAPE. Additionally, we enhance the dataset with skeleton annotations. Our code and data are publicly available.
Video
Results
Qualitative Results
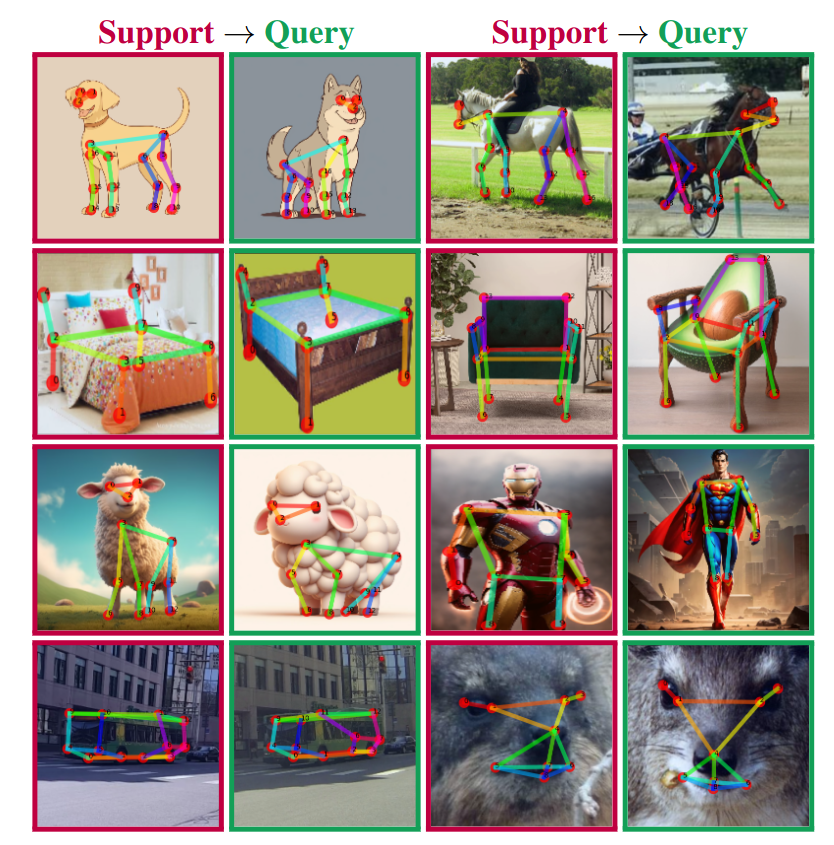
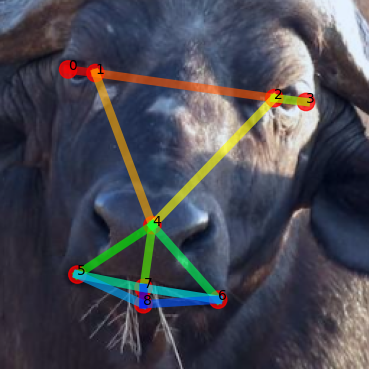
Using our method, given a support image and skeleton we can perform structure-consistent pose estimation on images from unseen categories.

Support
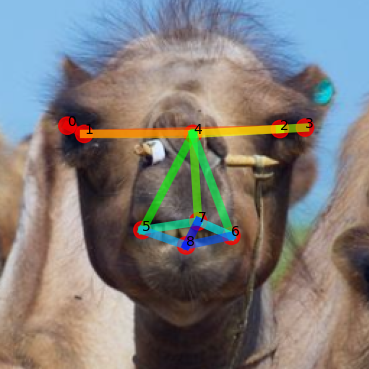
GT
Ours

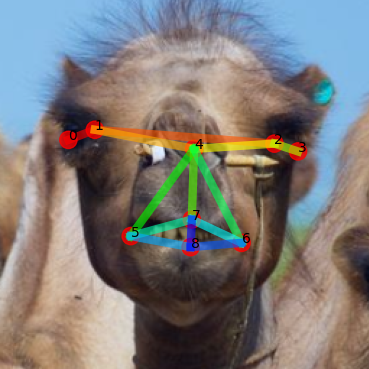
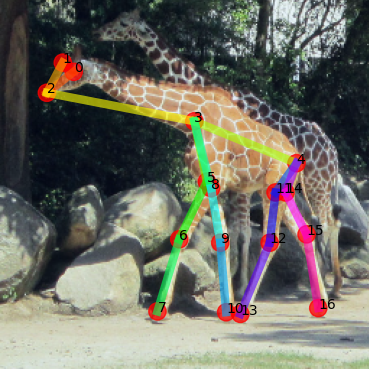
Support
GT
Ours
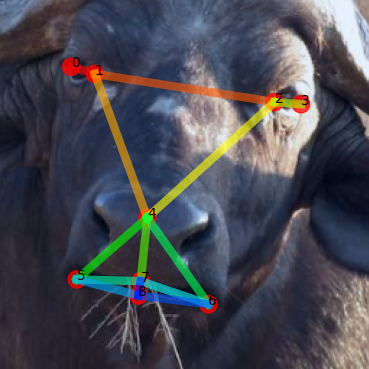
Support

GT
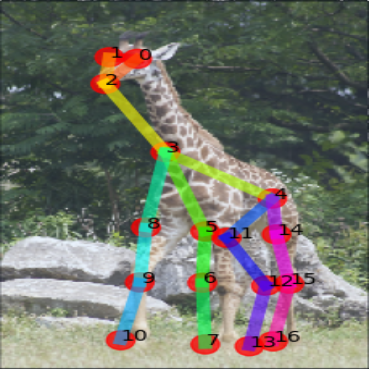
Ours

Support

GT

Ours

Support

GT

Ours

Support

GT

Ours
Out-of-Distribution
Our model, which was trained on real images only, demonstrates its adaptability and effectiveness across varying data sources such as cartoons and imaginary animals, created using a diffusion model. Furthermore, our model demonstrates satisfactory performance even when the Support and query images are from different domains.

Support

Ours

Support

Ours

Support

Ours

Support

Ours

Support

Ours

Support

Ours

Support

Ours
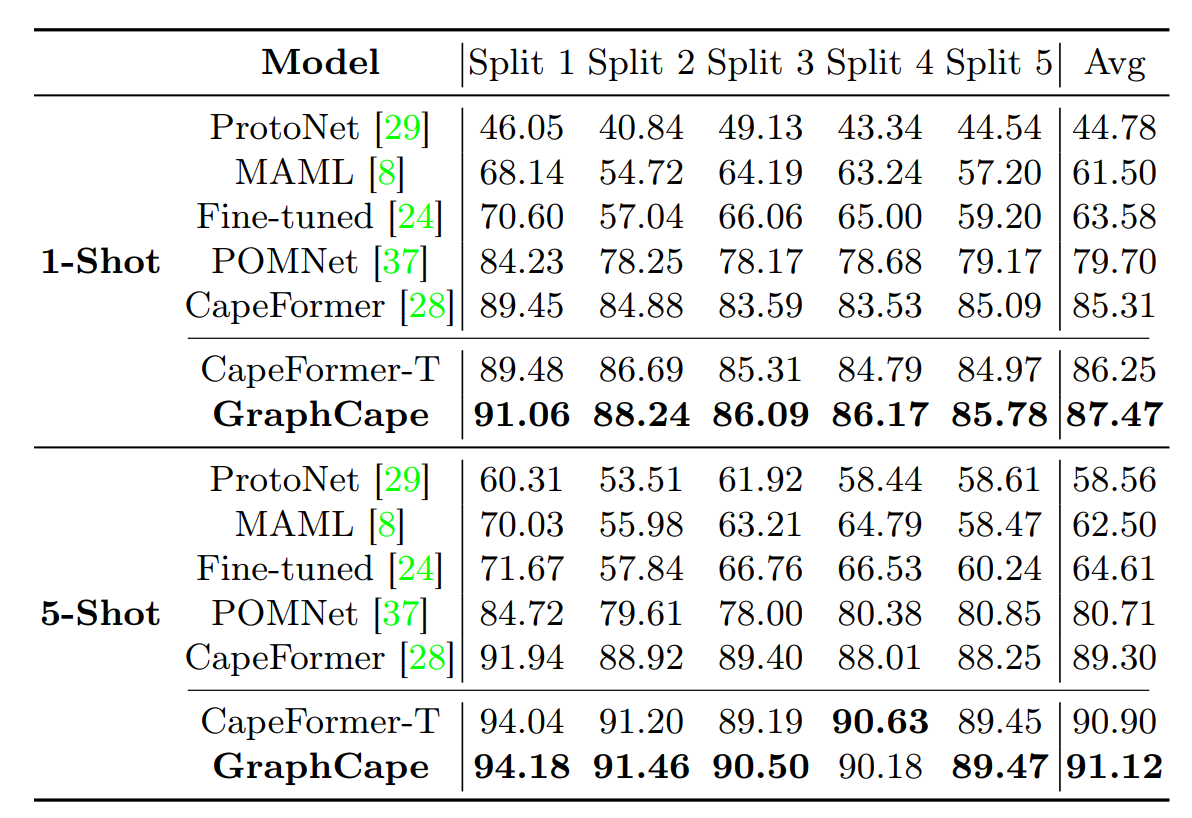
Quantitative Results
We compare our method with the previous CAPE methods CapeFormer and POMNet and three baselines: ProtoNet, MAML, and Fine-tuned. We report results on the MP-100 dataset under 1-shot and 5-shot settings. As can be seen, the enhanced baseline models, which are agnostic to the keypoints order as opposed to CapeFormer, outperform previous methods and improve the average PCK by 0.94% under the 1-shot setting and 1.60% under the 5-shot setting. Our graph-based method further improves performance, improving the enhanced baseline by 1.22% under the 1-shot setting and 0.22% under the 5-shot setting, achieving new state-of-the-art results for both settings. We also show the scalability of our design. Similar to DETR-based models, employing a larger backbone improves performance. We show that our graph decoder design also enhances the performance of the larger enhanced baseline, improving results by 1.02% and 0.34% under 1-shot and 5-shot settings respectively.
BibTeX
If you find this research useful, please cite the following:
@misc{hirschorn2023pose,
title={Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation},
author={Or Hirschorn and Shai Avidan},
year={2023},
eprint={2311.17891},
archivePrefix={arXiv},
primaryClass={cs.CV}
}