Method
Two orthogonal, test-time-only components that inject spherical geometry into pre-trained diffusion transformers.
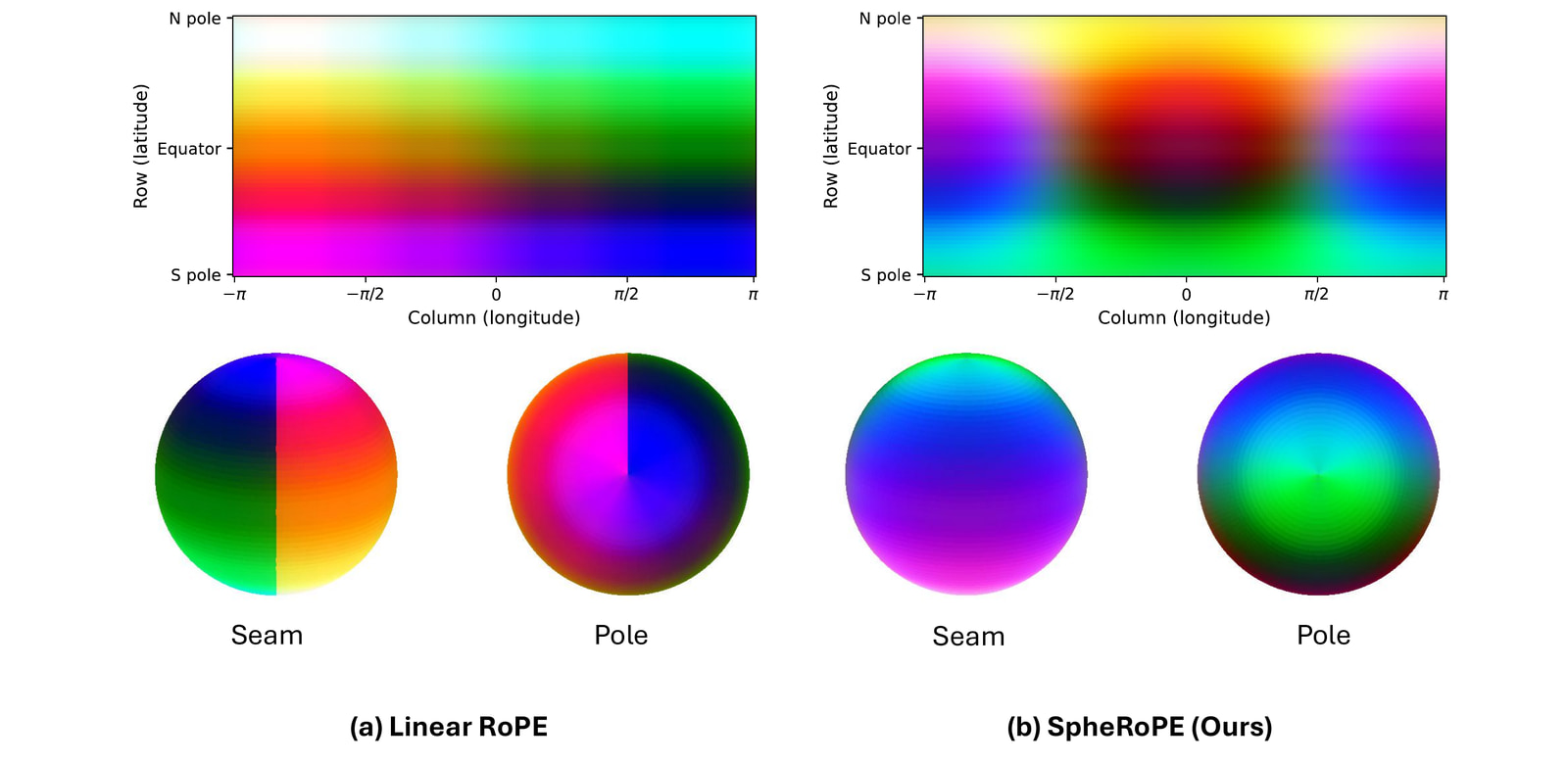
Spherical RoPE Positional Encoding
A valid ERP panorama must satisfy two topological constraints that standard linear RoPE fundamentally violates:
- C1. Horizontal periodicity — the left and right boundaries are the same meridian and must be continuous.
- C2. Polar convergence — all columns collapse to a single point at each pole.
Instead of one uniform fix, we partition the width-axis RoPE channels by their harmonic alignment with the image width and treat each band according to its role:
- Low-frequency channels act as a global compass. We re-parameterize them as Cartesian coordinates on the unit sphere so that, as longitude wraps, the embedding traces a closed loop (satisfying C1), and at the poles all columns converge to a single point (satisfying C2).
- High-frequency channels govern local texture. We keep them linear but snap each to the nearest integer harmonic of the width, enforcing exact 2π periodicity and eliminating seams without disturbing the pretrained local prior.
Semantic Distortion CFG Guidance
Pre-trained diffusion models already exhibit weak ERP behavior (polar stretching, horizon curvature) when prompted for 360° scenes. To amplify that latent prior and complement the hard geometry from Spherical RoPE, we extend classifier-free guidance to a three-way formulation:
The geometric term uses an anchored prompt — the user prompt concatenated with a geometric ERP description — so the difference εgeo−εcond isolates pure projection geometry, orthogonal to semantic content. The scales wsem and γ can be tuned independently; setting γ = 0 cleanly recovers standard CFG.